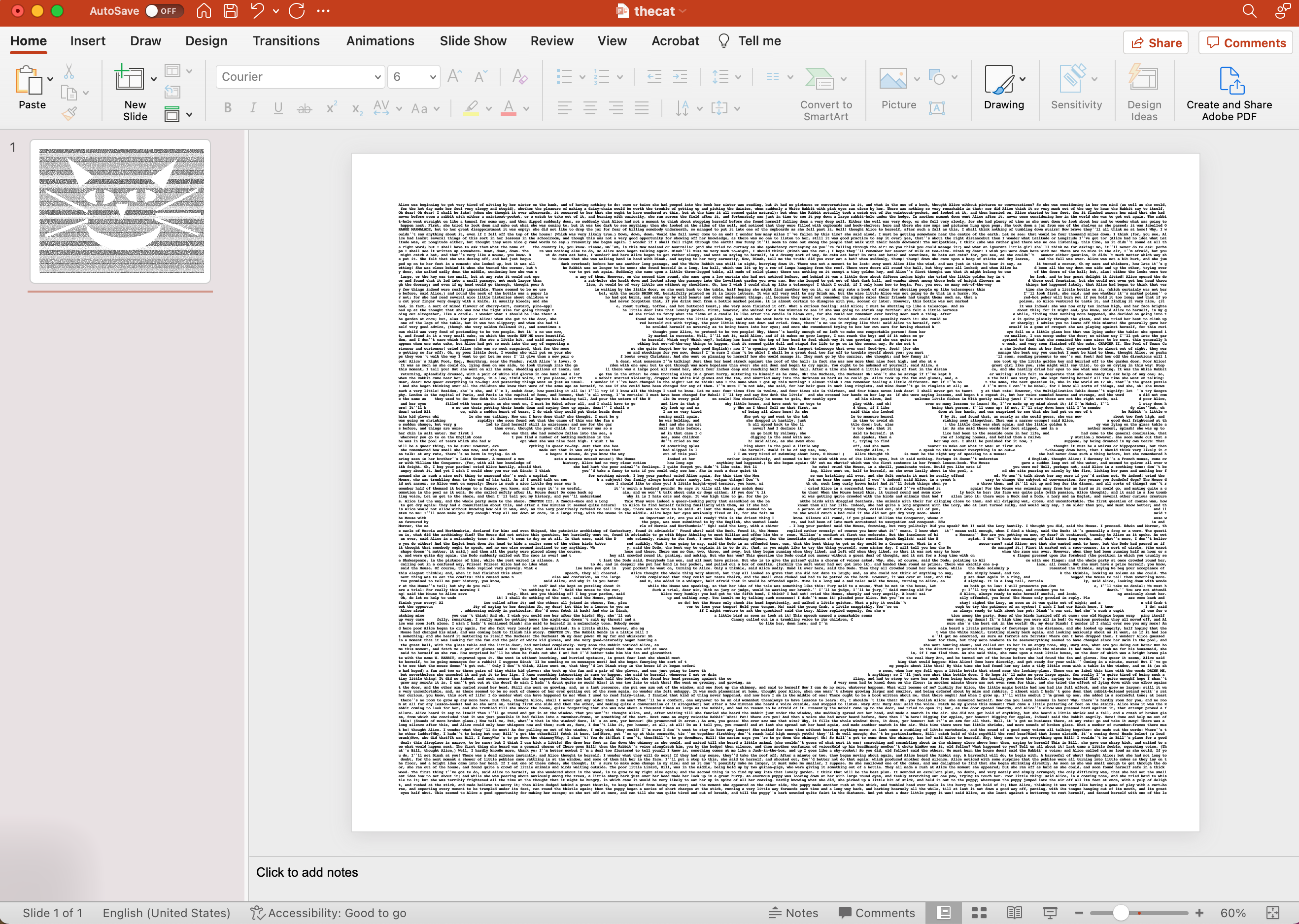
Python Word Art





A few years ago, I came across some beautiful art made by formatting the layout of text from well-known books. An image associated with the book was created by adjusting the space of the characters to form an elementary gray-scale image. By adding extra spaces in the text, you can reproduce pictures or designs representing the original book. The pictures above are from Alice in Wonderland, A Christmas Carol, and the poem Jabberwocky from Through the Looking Glass.
I decided to write a simple code to reproduce this idea. The underlying principle of the project is to convert an image into a mask and then format the text from a book to reflect this mask. There are five critical elements in this project:
- We must import Python libraries into the code.
- We need to download or access a long string of text that we will format into the art. Next, we will need to clean the text to remove any embedded control characters.
- We need to convert an image into a mask. First, we must rescale the image so the number of pixels maps into the available space for the text. Next, each row in this rescaled image must be scanned and associated with text strings. Finally, we place characters where the pixel values are above a set threshold, and blank spaces are embedded when they fall below this threshold.
- We need to convert the raw text into a file format to set the font type and size for printing.
- We need to pick an image and a source for the text and run the code.
You can download the sample code along with some of the graphics from Github.
You can browse the repository and clone it from here:
Importing the Needed Libraries.
To begin the code, we need to import some libraries. I've included the pip commands to install these libraries. You should only uncomment and execute the "pip install" lines the first time you run this on a new machine.
We start by grabbing elements of the python image library.
#pip install PIL import PIL.ImageGrab import PIL.ImageOps import PIL.Image
We then grab the python presentation library.
#pip install python-pptx from pptx import Presentation from pptx.util import Inches from pptx.util import Pt<br>
We use the requests library to grab data from the web:
#pip install requests import requests
Finally, we use the regular expression library. This library should be part of the standard python distribution.
import re<br>
Downloading Text From the Project Gutenberg
Before the internet was created, efforts were underway to move public domain documents into digital collections. One of the best examples of these collections is Project Gutenberg. This free digital collection has over 60,000 manuscripts. The books are usually available in various formats, from UTF-8 text to formats designed for multiple ebook readers.
As a geek (and data scientist), this data set is a goldmine for projects. You can search through their entire collection. They also maintain a list of the 100 most popular downloads.
For this project, I am using the UTF-8 version of the books. Once you pick a book you are interested in (like Alice in Wonderland), you can see the list of available formats available to download.
Reading a file into a python program is easy using the python request library.
import requests
data = requests.get("https://www.gutenberg.org/files/11/11-0.txt")
text = data.textOnce the file is downloaded and converted into text, we clean up the UTF-8 control characters. The easiest way to do this using the regular expression (re) library and python string replacements. In my code, I did the following steps:
First, get rid of the new lines and character returns.
text = re.sub("\r"," ",text)
text = re.sub("\n"," ",text)<br>Eliminate the asterisks, underline characters, and quotes because they mess up my formatting. I used the regular expression library for this change. I probably could have just used a text replacement.
<pre style="font-size: 13.5px;"> text = re.sub("\*", "", text)
text = re.sub("\_", "", text)
text = re.sub('"', '', text)<br>Remove all the quirky control characters associated with UTF-8. This code fixes the problems I found when I visually inspected the data in Jupyter notebook.
<pre style="font-size: 13.5px;"> text = text.replace("â\x80\x9d", "")
text = text.replace("â\x80\x9c", "")
text = text.replace("â\x80\x9c", "''")
text = text.replace("â\x80\x99","''")
text = text.replace("â\x80\x94","")
text = text.replace("â\x80\x98", "")Finally, I changed all the multiple spaces into a single space. Regular expressions are the easiest way to do this change. The "\s+" means all the occurrences of at least one white space.
<pre style="font-size: 13.5px;"> text = re.sub("\s+"," ", text)Using an Image to Format the Text Layout
Once we have some text, we need to format the letters to match the shape of an image.
First, we open the image and read it into the code.
# load the image img = PIL.Image.open(image_name)<br>
Next, I set up the parameters associated with the final text size.
# set up the margins for the text
text_width = slide_width - 2*slide_left_margin
text_height= slide_height - 2*slide_top_margin<br>Now we can calculate the number of characters that will fit in the text box. The first step is to determine how big the font is in inches. The 60 and 120 in the code were found experimentally based. These numbers SHOULD probably be 72 and 144 based on my understanding of point sizes in formatting, but I needed to adjust them slightly.
vscale = 60 / font_size
hscale = 120 / font_size<br>Next, we resize the image so the number of pixels in the new image corresponds to the number of characters available in the text field. To determine this number, we have to multiply the text width times scaling factor from above.
nw = int(text_width * hscale)
nh = int(text_height * vscale)
img3 = img.resize((nw, nh))<br>Now we need to convert this image into simple one-byte grayscale and invert it if desired:
gray = img3.convert("L")
if invertBW:
gray = PIL.ImageOps.invert(gray)<br>The next thing I do is convert the pixels in this image into a one-dimensional list. I could have sampled the pixel values one at a time, but this seemed a bit more natural to me.
a = list(gray.getdata())<br>
This list is the key to the whole project. The size of the list is the product of the length and width (in pixels) of the newly resized image. Each value in the list is between 0 and 255, so we can determine if it should be a blank or a character based on this pixel value.
We will now loop through image pixels. However, before that, we need to set up a few counters.
- text_counter is the current location within our downloaded text
- pixel_counter is the current location within the long list of pixel values
- plist is a list of paragraphs we will be creating with the formatted text. Each paragraph is a line of formatted text.
- threshold is the value above which we consider pixel to be dark. Usually, we pass this value into the function as a parameter, but I include it here for completeness.
text_counter = 0
character_counter = 0
plist = []
threshold = 128<br>We will now loop over the image by row and column. The rows are associated with the number of pixels in the image height. The number of columns is related to the image width. The ft variable is the formatted text for this paragraph. The outer loop structure looks like this:
for i in range(nh):
fT = ""
for j in range(nw): <br>We can now determine if the current pixel is above the threshold. If it is, we add the next character and update the text_counter. If it is below the threshold, we add a blank space and don't update the text_counter. After we append the character to our formatted text string (ft), we update the pixel_counter. I could simplify the code a bit, but I wanted to ensure it was straightforward for less experienced programmers.
c = a[pixel_counter]
add_character = ( c>= threshold)
if add_character:
fT = fT + text[text_counter]
text_counter = text_counter + 1
else:
fT = fT + " "
pixel_counter = pixel_counter + 1
We append the text string into the paragraph list at the end of each row.
plist.append(fT)<br>
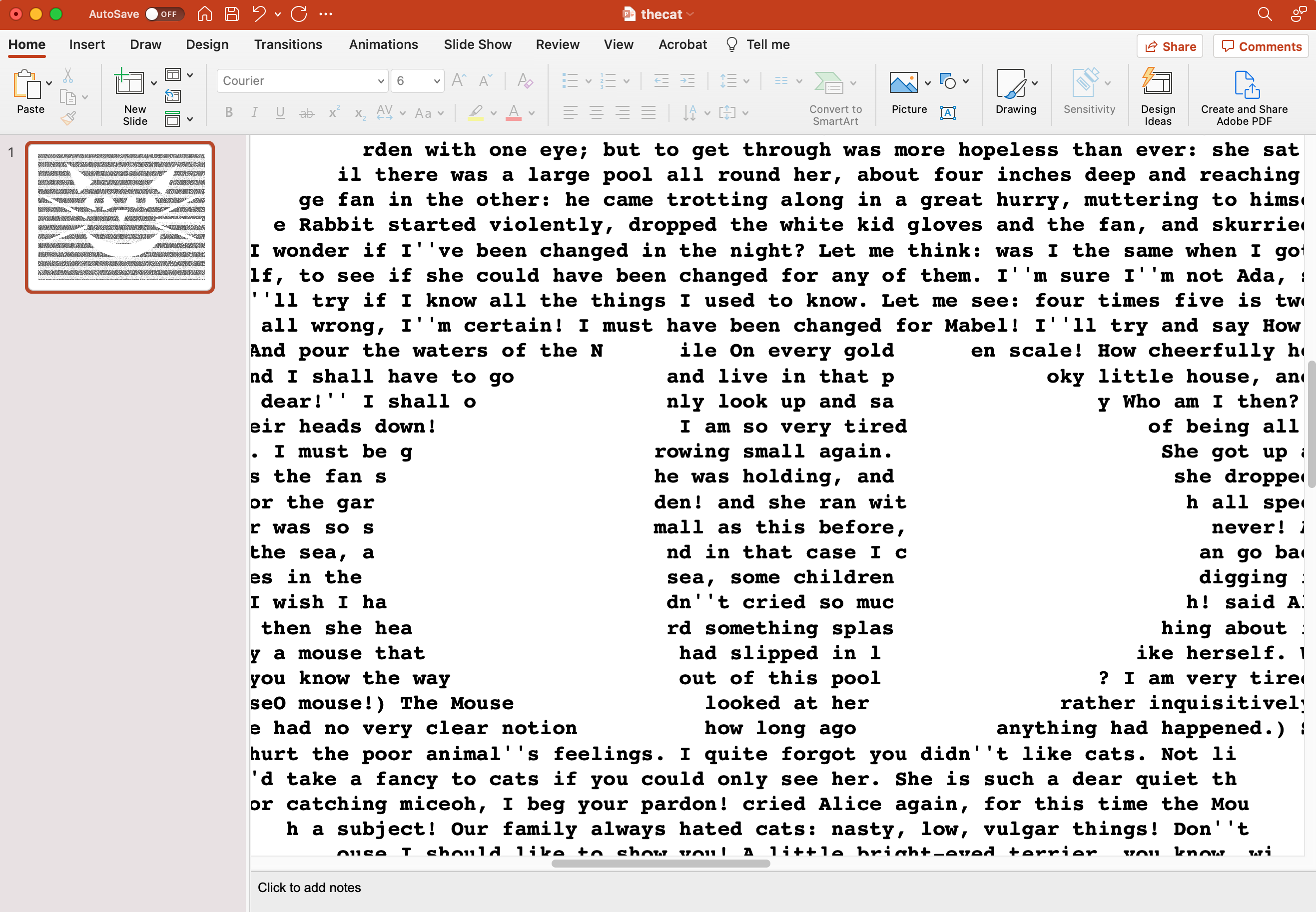
Text from the original book is formatted around the white space associated with locations in the image.
Reformatting the Image Into a Printable Form
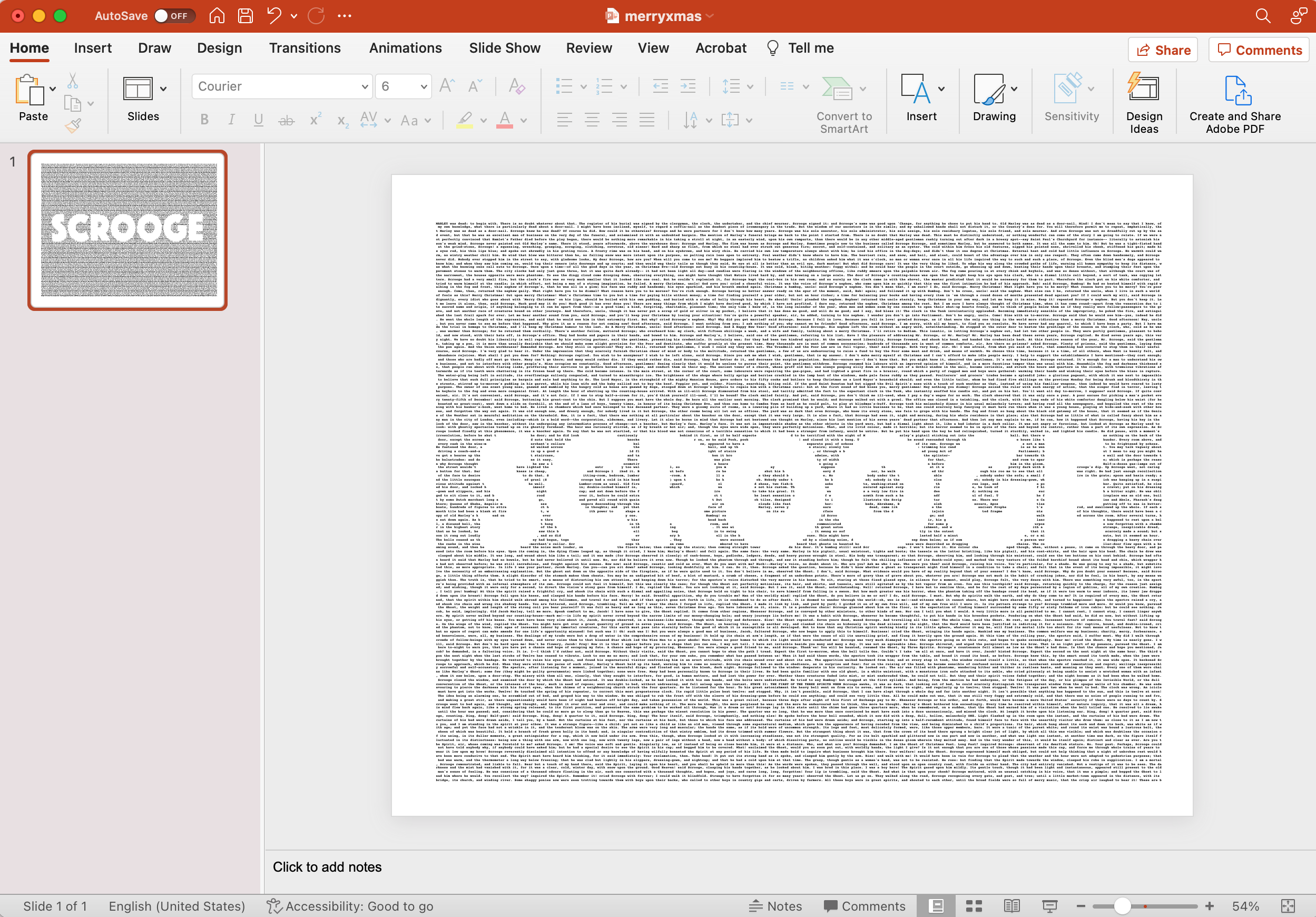
The final step in this process is putting the text into a format that is easy to print. I decided to use Powerpoint for the final document. I probably could have used Word or PDF, but Powerpoint is relatively universal. You can bring a Powerpoint slide into your local copy/printing center and ask them to print it as a large poster.
For this step, I used the python-pptx library in the code. However, setting up this library was a little confusing, so let me explain the sequence you need to follow for using this library.
First, we need to create the presentation. Next, we need to set the slide height and width in inches. In the code, the Inches routine is part of the pptx library. Finally, we need to select the slide format as a blank slide. Based on experimentation, 6 is the number associated with this layout.
prs=Presentation()
prs.slide_width = Inches(slide_width)
prs.slide_height = Inches(slide_height)
lyt=prs.slide_layouts[6] <br>Within the slide, we are going to create a textbox. I am setting the textbox bounds based on the slide size and the margins on the sides and top/bottom. So first, I define the textbox with the left, top, width, and height variables. I used these values in the next step.
text_width = slide_width - 2*slide_left_margin
text_height= slide_height - 2*slide_top_margin
left = Inches(slide_left_margin)
top = Inches(slide_top_margin)
width = Inches(text_width)
height = Inches(text_height)<br>I will now create a new slide in the presentation and add a textbox. Finally, I construct a text frame to accept the paragraphs of the formatted text.
slide=prs.slides.add_slide(lyt)
text_box=slide.shapes.add_textbox(left, top, width, height)
tb=text_box.text_frame<br>Now I can create our paragraphs and add the text associated with the paragraph list (plist).
for pp in plist:
pgr = tb.add_paragraph()
pgr.text=pp <br>Finally, I set the font and font size for each paragraph. We will loop through the paragraphs and set these variables. I could have done this in the previous step, but I wanted to make it easier to read. It is important to note that not all fonts will work well with this type of art. For example, Courier is a monospaced font; thus, all characters have the same width.
for i in range(len(tb.paragraphs)):
tb.paragraphs[i].font.size = Pt(font_size)
tb.paragraphs[i].font.name = 'Courier' # use a monospace font <br>Finally, we save the output file as a Powerpoint file. The name generally should have the "pptx" extension.
prs.save(output_name) <br>
Creating Word Art

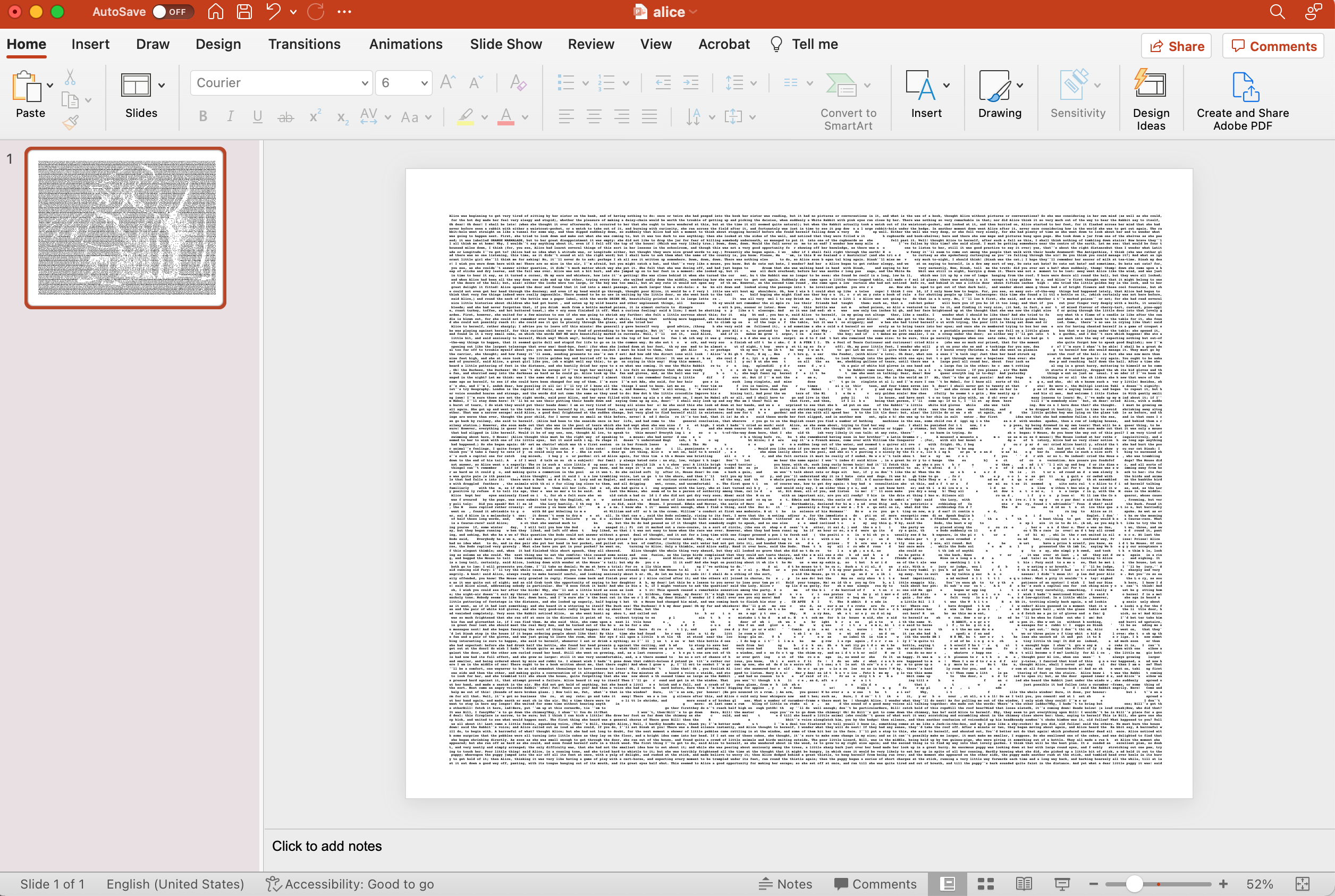
Since I organized the python notebook into a few simple functions, using this code is pretty straightforward.
To help people get started, I set up some example book metadata from Project Gutenberg. Each record contains the book's title, the author, the URL where you can access it, and the text associated with the first line.
book_data = [
{
"title":"A CHRISTMAS CAROL IN PROSE BEING A Ghost Story of Christmas",
"author":"Charles Dickens",
"url":"https://www.gutenberg.org/cache/epub/46/pg46.txt",
"firstLine":"MARLEY was dead: to begin with"
},
{
"title":"Alice’s Adventures in Wonderland",
"author":"Lewis Carroll",
"url":"https://www.gutenberg.org/files/11/11-0.txt",
"firstLine":"Alice was beginning to get very tired"
},
{
"title":"War of the Worlds",
"author":"H. G. Wells",
"url":"https://www.gutenberg.org/cache/epub/36/pg36.txt",
"firstLine":"No one would have believed"
},
....
]<br>The book data is then loaded using:
data = requests.get( book["url"]) istart = data.text.find(book["firstLine"]) text = data.text[istart:]<br>
Although you can theoretically use any image for this project, simple is the best. A paint program is the best way to create these images. You could also use pictures and then run them through a photo editor to simplify the outlines. For example, the picture above was made from a relatively complex drawing by Sir John Tenniel for the original Alice in Wonderland book. Although Alice is visible in the formatted text, the original picture needs editing to sharpen the resulting image.
I hope you experiment with this project. For example, adding bold or color text could make the image more interesting. (Hint: text "runs" within the pptx library can help with this.) Changing the direction to follow the outline of objects would also be fun.
Although it was fun to format classic texts into graphically attractive layouts, you could use this program with papers, reports, and even thesis projects.
Have fun experimenting with the code! Also, please post some of the art you create with it!